Googleアナリティクスで自分のアクセスを除外する方法(IP除外設定)
概要
- 自分のアクセスでブログのアクセス数が増加し正確なデータが取得できないため、自分の利用しているIPを除外設定する方法を記載します
環境
- Googleアナリティクス4
Table of Contents
自分の利用しているIPアドレスの確認
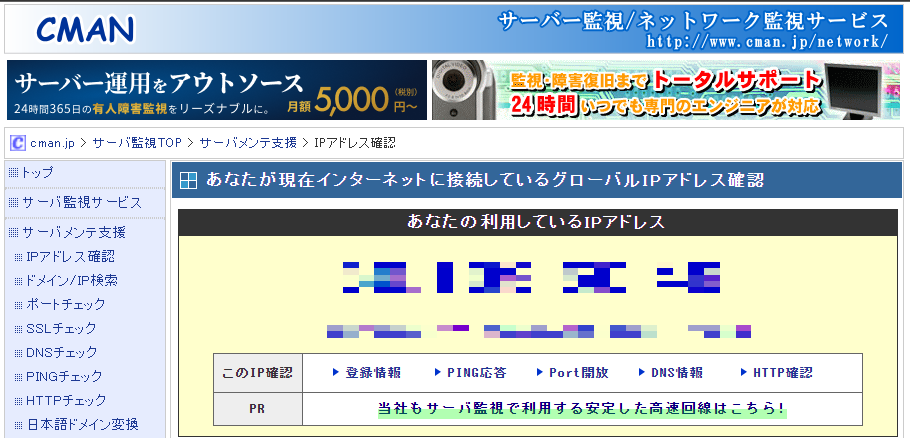
GoogleアナリティクスでIPアドレスの除外設定
Googleアナリティクスのホーム画面から左下の[管理]をクリック
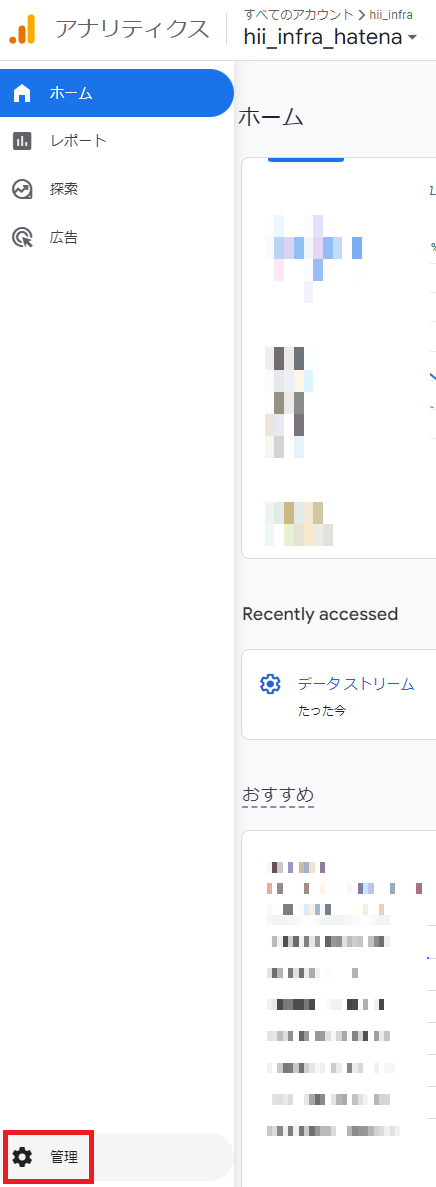
管理タブの[データストリーム]をクリック
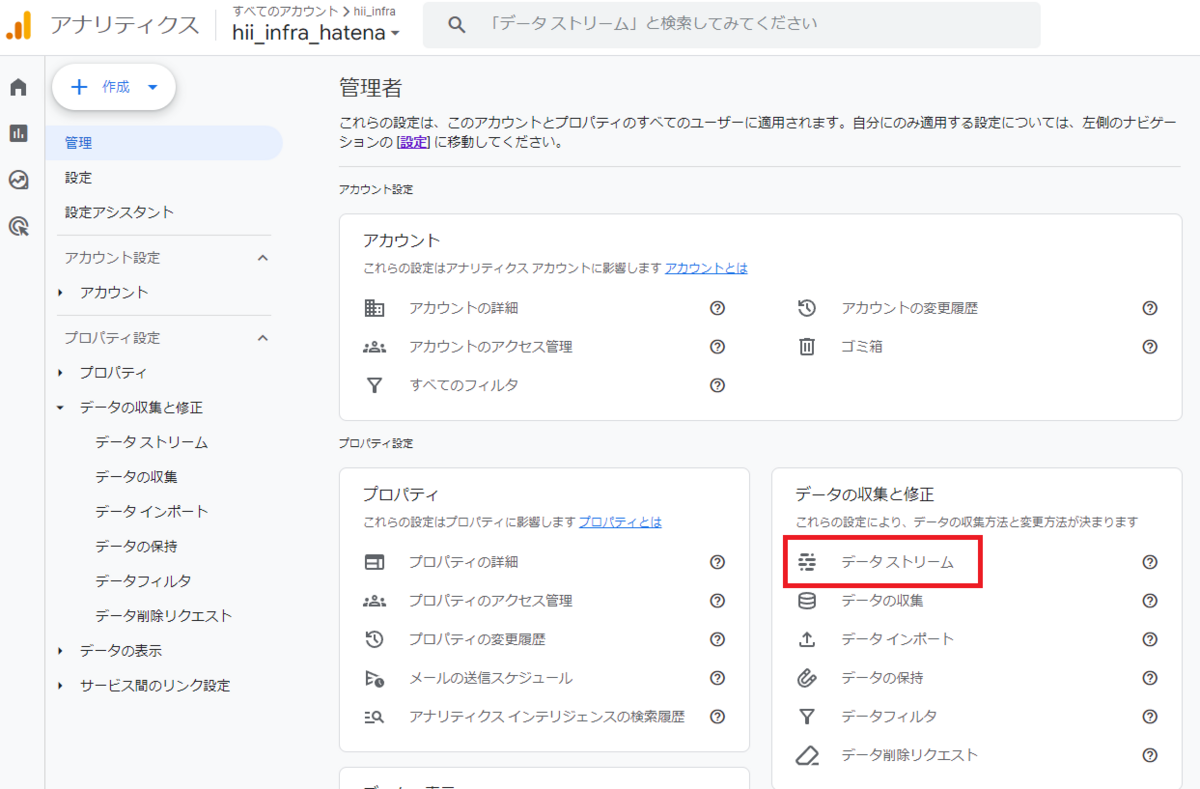
対象のWebサイトをクリック

[タグ設定を行う]をクリック
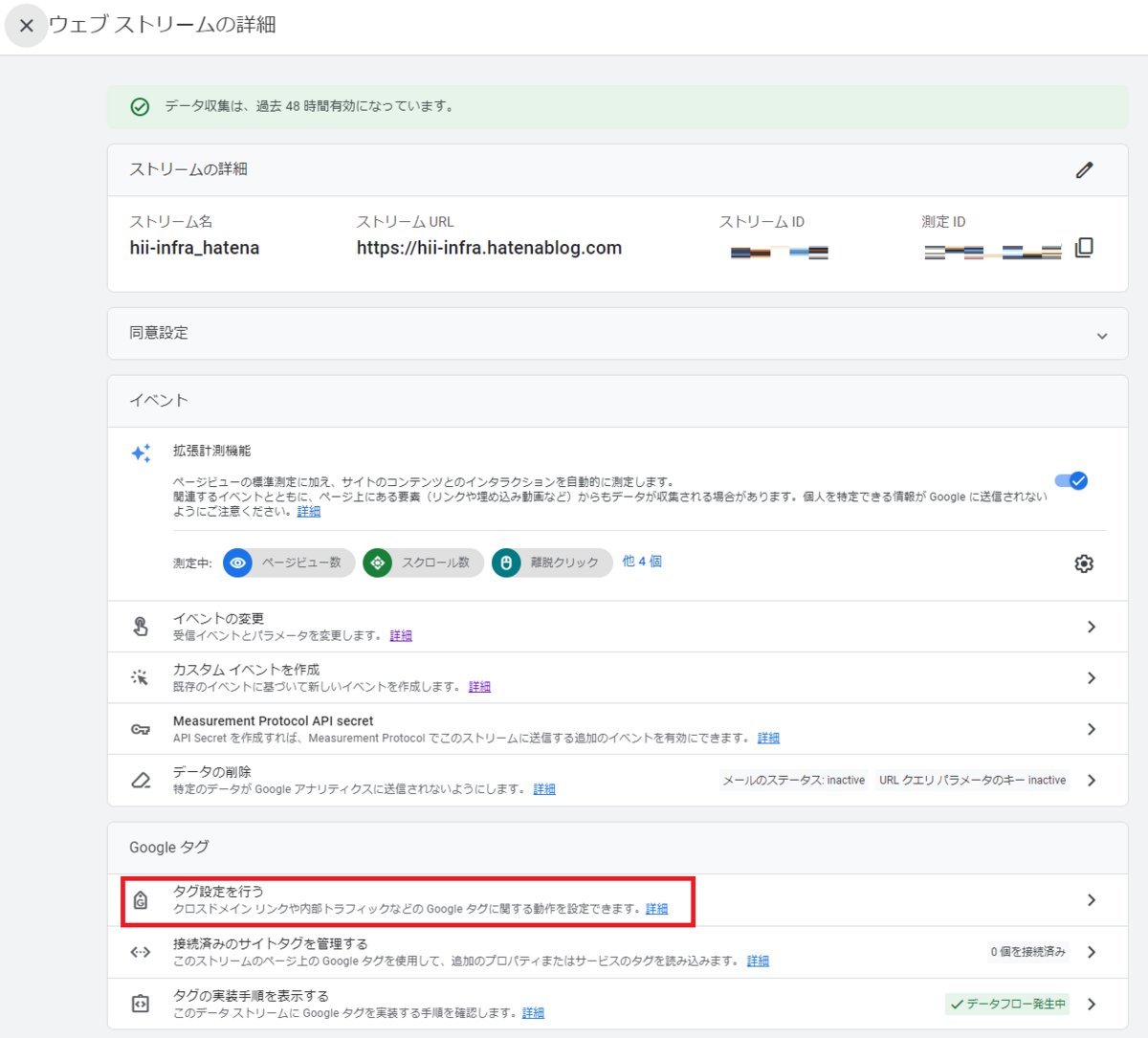
[内部トラフィックの定義]をクリック
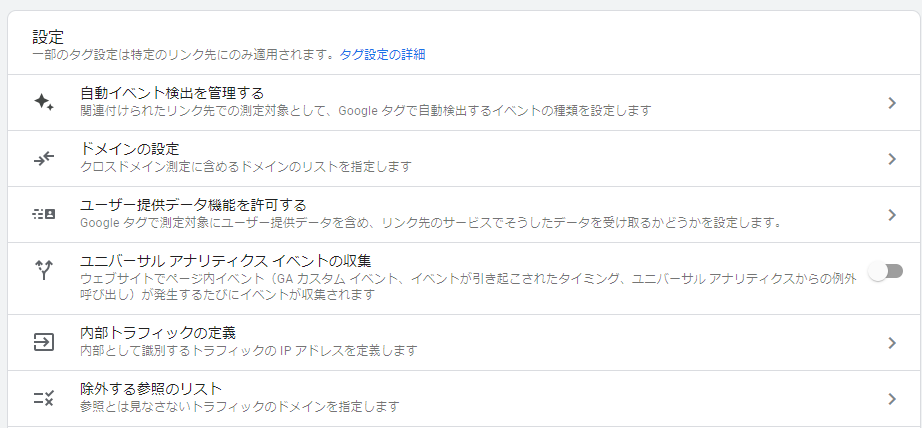
[作成]をクリック

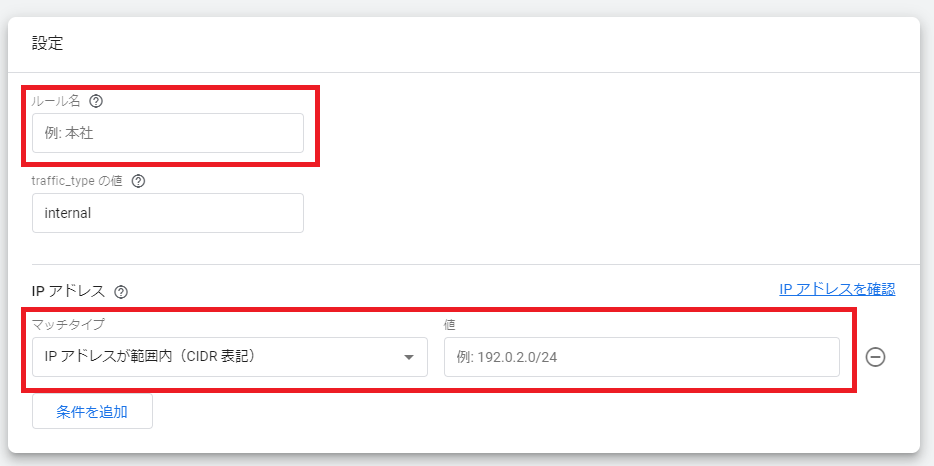
ルール名とIPアドレスの項目を記載し作成をクリック
作成したルールが表示されていれば作成完了です!
リンク
Linuxのディスクやファイルの容量確認方法
概要
- Linuxサーバのディスク使用量やファイルの容量を調べるためのコマンドを紹介します
環境
- RHEL9.4
Table of Contents
ディスク使用量確認コマンド
dfコマンドでディスクサイズを確認できます-hオプションで人にわかりやすい単位で表示してくれます
# df -h Filesystem Size Used Avail Use% Mounted on devtmpfs 4.0M 0 4.0M 0% /dev tmpfs 3.8G 0 3.8G 0% /dev/shm tmpfs 1.5G 9.1M 1.5G 1% /run /dev/mapper/rhel-root 61G 3.0G 58G 5% / /dev/nvme0n1p2 1014M 279M 736M 28% /boot /dev/nvme0n1p1 599M 7.1M 592M 2% /boot/efi /dev/mapper/rhel-home 30G 245M 30G 1% /home tmpfs 766M 0 766M 0% /run/user/0
# df /home Filesystem Size Used Avail Use% Mounted on /dev/mapper/rhel-home 30G 245M 30G 1% /home
ディレクトリの容量確認コマンド
duコマンドでカレントディレクトリ配下のすべてのディレクトリの容量を確認できます-hオプションで人にわかりやすい単位で表示してくれます-aオプションでファイルを含めた容量を確認できます
- ディレクトリ名を指定することで対象のディレクトリの容量を一覧で表示できます
# du -h /tmp 0 /tmp/systemd-private-08c52211b7e14963b5a4c95ab4ae7cd1-dbus-broker.service-8xSAvh/tmp 0 /tmp/systemd-private-08c52211b7e14963b5a4c95ab4ae7cd1-dbus-broker.service-8xSAvh 0 /tmp/systemd-private-08c52211b7e14963b5a4c95ab4ae7cd1-chronyd.service-3rKmKa/tmp 0 /tmp/systemd-private-08c52211b7e14963b5a4c95ab4ae7cd1-chronyd.service-3rKmKa 0 /tmp/systemd-private-08c52211b7e14963b5a4c95ab4ae7cd1-systemd-logind.service-CkSGIh/tmp 0 /tmp/systemd-private-08c52211b7e14963b5a4c95ab4ae7cd1-systemd-logind.service-CkSGIh 0 /tmp/vmware-root_878-2697663918 0 /tmp/systemd-private-08c52211b7e14963b5a4c95ab4ae7cd1-kdump.service-EX9rep/tmp 0 /tmp/systemd-private-08c52211b7e14963b5a4c95ab4ae7cd1-kdump.service-EX9rep 4.0K /tmp
-sオプションで指定したディレクトリの合計サイズを確認できます
du -sh /tmp/* 0 /tmp/systemd-private-08c52211b7e14963b5a4c95ab4ae7cd1-chronyd.service-3rKmKa 0 /tmp/systemd-private-08c52211b7e14963b5a4c95ab4ae7cd1-dbus-broker.service-8xSAvh 0 /tmp/systemd-private-08c52211b7e14963b5a4c95ab4ae7cd1-kdump.service-EX9rep 0 /tmp/systemd-private-08c52211b7e14963b5a4c95ab4ae7cd1-systemd-logind.service-CkSGIh 0 /tmp/vmware-root_878-2697663918
Google AI(Gemini)のAPIをPythonで利用してみる
概要
環境
- Python 3.9.14
Google AI StudioでAPI key取得
- Google AI StudioでAPI keyを取得する
Pythonコード作成
- 以下サンプルコード
GOOGLE_API_KEYはハードコードしないことが推奨されていますが、今回はAPI利用の検証目的のため直接記載しました。
import google.generativeai as genai genai.configure(api_key='GOOGLE_API_KEY') model = genai.GenerativeModel(model_name="gemini-1.5-flash") response = model.generate_content("日本について") print(response.text)
Perl基礎構文
概要
環境
- OS
- OracleLinux 9.1
- Perl
- 5.32.1
Table of Contents
- Perlを書き始める際のおまじない文
- 文字の出力
- スカラー変数
- 四則演算
- 文字列連結
- 演算の順番
- コマンドライン引数
- if文
- 配列
- forループ
- 配列の操作
- ハッシュ
- サブルーチン
- リファレンス
- デリファレンス
- 正規表現
- PerlでWeb API
Perlを書き始める際のおまじない文
- perlでプログラムを書く際、ファイルの一番最初に書くおまじない文です。
#!/usr/bin/env perl: このプログラムがperlで動くことを明示する記載use strict;: 厳密な書式で書くことを強制し、未定義の変数を警告するuse warnings;: 望ましくいない記述を警告する
#!/usr/bin/env perl use strict; use warnings;
文字の出力
- 文字を出力する場合は
printを利用して記載する
#!/usr/bin/env perl use strict; use warnings; print "Hello World!\n";
スカラー変数
- Perlの変数には
スカラ変数、配列、ハッシュがあるスカラ変数($): 1つの要素を格納する配列(@): 複数の要素を順番に格納するハッシュ(%): 複数の要素を名前=>の組み合わせで格納する
変数の利用
- 変数を初めて使うときは先頭に
myをつける - スカラ変数の先頭には
$をつける- $は
scalarのs
- $は
#!/usr/bin/env perl use strict; use warnings; my $foo; $foo = 1; print "$foo\n"; $foo = "Hello World"; print "$foo\n";
- 出力結果
1 Hello World
- 変数の宣言と同時に値を代入することもできる(こっちが主流っぽい)
#!/usr/bin/env perl use strict; use warnings; my $foo = 1; print "$foo\n";
クォーテーションによる表示の違い
- 変数の中身を表示する場合は
"(ダブルクォーテーション)の中に記載する - 記載しているそのままの内容を表示するには
'(シングルクォーテーション)で記載する
#!/usr/bin/env perl use strict; use warnings; my $foo = 1; print "$foo\n"; print '$foo\n';
- 出力結果
1 $foo\n
四則演算
- ほかの言語の同じような記載で問題なし
#!/usr/bin/env perl use strict; use warnings; my $foo = 4; my $bar = 2; my $result; # 足し算 $result = $foo + $bar; print "$foo + $bar = "; print "$result\n"; # 引き算 $result = $foo - $bar; print "$foo - $bar = "; print "$result\n"; # 掛け算 $result = $foo * $bar; print "$foo * $bar = "; print "$result\n"; # 割り算 $result = $foo / $bar; print "$foo / $bar = "; print "$result\n"; # べき乗 $result = $foo ** $bar; print "$foo ** $bar = "; print "$result\n"; # 剰余 $result = $foo % $bar; print "$foo % $bar = "; print "$result\n";
- 出力結果
4 + 2 = 6 4 - 2 = 2 4 * 2 = 8 4 / 2 = 2 4 ** 2 = 16 4 % 2 = 0
文字列連結
.で文字列や変数を連結することができる- 連結した文字列や変数を、別の変数に代入することも可能
#!/usr/bin/env perl use strict; use warnings; my $word = 'word'; my $num = '123'; print "$word$num\n"; print $word . $num . "\n"; my $str = $word . $num; print $str . "\n";
- 出力結果
word123 word123 word123
演算の順番
- 演算の優先順位と結合方向はperldocのperldoc.jp - Perlの演算子と優先順位に詳細が記載されています
- コードを見た人が理解するためにも下記のようにわかりやすい記述をする
- ()で演算の順番を明確に示す
- 数値演算と文字列の連結は分けて記載する
#!/usr/bin/env perl use strict; use warnings; my $num1 = 2 + 4 * 3; print "$num1\n"; my $num2 = ( 2 + 4 ) * 3; print "$num2\n"; # 数値演算と文字列演算を分けないで記載した悪い例 my $now = 2024; my $my_birth_year = 2012; print "I am" . $now - $my_birth_year . "years old\n"; # 数値演算と文字列演算を分けた例1 print "I am" . ( $now - $my_birth_year ) . "years old\n"; # 数値演算と文字列演算を分けた例2 my $age = $now - $my_birth_year; print "I am" . $age . "years old\n";
- 出力結果
14 18 Argument "I am2024" isn't numeric in subtraction (-) at enzan_priority.pl line 17. -2012years old I am12years old I am12years old
コマンドライン引数
- コマンドライン引数を設定する場合はターミナルで下記のように記載します
# 引数が1つの場合 perl single.pl "arg" # 引数が複数の場合 perl multi.pl "arg1" "arg2"
#!/usr/bin/env perl use strict; use warnings; my $first = shift; my $second = shift; print 'first is ' . "$first\n"; print 'second is ' . "$second\n";
- 出力結果(
perl cli_args.pl "aaa" "bbb"を実行)
first is aaa second is bbb
if文
- Perlにはtrue/falseがありません
- ほかのプログラミング言語ではtrueやfalseという単語に真または偽の意味を持たせたキーワードとして扱うことがある
- 後述する5つの偽値のみが偽、それ以外はすべて真となります
Perlにおける真と偽の値
- Perlでは次の5つの値が
偽として扱われ、これ以外の値はすべて真として扱われます- 数値
0 - 文字列
0 - 文字列
''(シングルクォーテーションの連続、間に何もない。空文字ともいう) - 空のリスト
() - undef(値が入っていないスカラー変数)
- 数値
if文の構文
if ( 条件式 ) { 条件式の結果が真の場合に実行されるブロック; } else { 条件式の結果が偽の場合に実行されるブロック; }
- サンプルコード
#!/usr/bin/env perl use strict; use warnings; if ( 0 ) { print "OK\n"; } else{ print "NG\n" }
- 出力結果
NG
比較演算子
- 数値の比較演算子
== # 右辺と左辺が等しいならば真 != # 右辺と左辺が等しくないならば真 < # 右辺より左辺が小さいならば真 > # 右辺より左辺が大きいならば真 <= # 右辺が左辺以上ならば真 >= # 右辺が左辺以下ならば真
- 文字列の比較演算子
ltやgtで比較する文字列の大小は文字列の長さではなく、辞書順に並べた時に前にくるものが小さく、後ろに来るものが大きいと判断されます
eq # equal ne # not equal gt # greater than ge # greater equal lt # less than le # less equal
複数の条件分岐
elsifを使うことで、分岐条件を増やすことができますelse ifではなくelsifなので要注意(ほかの言語と混同しちゃいそう)
サンプルコード
#!/usr/bin/env perl use strict; use warnings; my $num = 3; if ($num == 1 ) { print "OK\n"; } else{ print "NG\n" } my $foo = 'hello'; if ($foo eq 'hello' ) { print "OK\n"; } else{ print "NG\n" } if ($num == 1) { print "$num is One" . "\n"; } elsif ($num == 2 ) { print "$num is Two" , "\n"; } elsif ($num == 3 ) { print "$num is Three" , "\n"; } else { print "$num is not even One, even Two, even Three" , "\n"; }
- 出力結果
NG OK 3 is Three
論理演算子
- if文の条件式でより複雑な条件を扱いたいときは論理演算子を用いて複数の条件を連結します
&& # かつ || # または
#!/usr/bin/env perl use strict; use warnings; my $num = 10; if ( $num > 0 && $num % 2 == 0 ) { print "&& : OK\n"; } else{ print "&& : NG\n"; } if ( $num > 0 || $num % 2 == 1) { print "|| : OK\n"; } else{ print "|| : NG\n"; } my $small = 10; my $medium = 20; my $large = 30; if ( $small < $medium <= $large ) { print "小さい順に並んでいます\n"; }
- 出力結果
&& : OK || : OK 小さい順に並んでいます
配列
- 複数の値や複数のスカラー変数をまとめて扱うことができるもの
- 配列を作る場合は変数名の前に
@をつけます@はアレイ(array)、@rrayと覚えるといいらしいです
- 配列から要素を利用する際は添字を使います
- 配列の添字は数字で指定します
- 配列の先頭の要素の添字は0となり、末尾に向けて1ずつ増えます
- 配列の要素に代入することもできます
- 配列に別の配列の中身を追加することもできます
- 配列の要素数を取得する場合は、scalar関数の引数に配列を与えることで要素の個数を取得できます
- 配列
@arrayに対して@#arrayと書くことで、配列に格納されている末尾の要素の添字を取得できます - 連続する数字を配列に格納するときは範囲演算子
..が便利です(1 .. 5)- 左の数値より右側の数値が大きいことが条件になります
#!/usr/bin/env perl use strict; use warnings; my @array = ( 1, "foo", 3 ); # 配列と配列の要素出力 print "@array" . "\n"; print "$array[0]" . "\n"; print "$array[1]" . "\n"; print "$array[2]" . "\n"; # 配列の要素に代入 $array[0] = "bar"; print "@array" . "\n"; # 配列に別の配列の追加 my @array_one_two = ( 1, 2 ); my @array_numbers = ( @array_one_two, 3 ); print "@array_numbers" . "\n"; # 配列の要素数の取得 my $count_array_element = scalar @array; print "$count_array_element\n"; # 配列の末尾の要素の添字 my $last_array_index = $#array; print "$last_array_index\n"; # 範囲演算子 my @array1 = ( 1 .. 5 ); print "@array1\n";
- 出力結果
1 foo 3 1 foo 3 bar foo 3 1 2 3 3 2 1 2 3 4 5
forループ
- 配列の要素を順番にすべて処理する場合にfor文があります
- for文と範囲演算子を組み合わせることで、決まった回数処理を繰り返すことができます
#!/usr/bin/env perl use strict; use warnings; my @array = ( 1, "foo", 3 ); for my $element (@array){ print "$element\n"; } # カウントアップ for my $i ( 1 ... 5 ){ print "$i\n"; } # 単なる繰り返し for my $i ( 1 ... 5 ){ print "Hello world\n"; }
- 出力結果
1 foo 3 1 2 3 4 5 Hello world Hello world Hello world Hello world Hello world
配列の操作
配列操作の関数
- join, split
- sort, reverse
- 配列を並べ替える、逆順にする
- pop, shirt, push, unshift
- 配列から要素を取り出す、要素を追加する
join
- リストや配列の要素を連結して、スカラー値にする関数です
- joinが受け取る第1引数は、リストや配列の要素をくっつける糊のような役割を果たします
- 第2引数には、対象の配列やリストを渡します
#!/usr/bin/env perl use strict; use warnings; my @words = ( 'I', 'Love', 'Perl.' ); my $poem = join '_', @words; print $poem . "\n"
- 出力結果
I_Love_Perl.
split
- 指定したパターンに従ってスカラー値や文字列を分割し、リストにします
#!/usr/bin/env perl use strict; use warnings; my $poem = 'I_Love_Perl.'; my @words = split /_/, $poem; print "@words\n"
- 出力結果
I Love Perl.
sort
- 配列をルール順に並べ替えて、その配列を返します
sortのみ、あるいはsort { $a cmp $b } @arrayと書くと、文字列として昇順に並べ替えます- 数値を昇順に並べ替えると、先頭の文字で判断して並べ替えられます。
- 数値の大小で並べ替える場合は
sort { $a <=> $b } @arrayと記載します - 変数
$aと$bはsortで使うために予約されているので、sort以外で使わないようにしましょう
- 数値の大小で並べ替える場合は
#!/usr/bin/env perl use strict; use warnings; my @lang = ( 'perl', 'php', 'ruby', 'python', 'java', 'go' ); my @sorted_lang = sort @lang; print "@sorted_lang" . "\n"; my @num = ( 5, 200, 40, 3, 1 ); my @sorted_num = sort @num; print "@sorted_num" . "\n"; my @sorted = sort { $a <=> $b } @num; print "@sorted" . "\n";
- 出力結果
go java perl php python ruby 1 200 3 40 5 1 3 5 40 200
reverse
- リストを逆順に並べ替えて、そのリストを返す関数です
#!/usr/bin/env perl use strict; use warnings; my @array = reverse ( 1 .. 5 ); print "@array" . "\n";
- 出力結果
5 4 3 2 1
push/pop
- push/popは配列の末尾の要素を操作する関数です
- 配列の末尾に要素を追加するときはpushを利用します
- 配列の末尾から要素を取り出すときはpopを利用します
#!/usr/bin/env perl use strict; use warnings; my @members = ( 'Alice', 'Bob' ); push @members, 'Carol'; print "@members" . "\n"; my @member = pop @members; print "@members" . "\n"; print "@member" . "\n";
- 出力結果
Alice Bob Carol Alice Bob Carol
unshift/shift
- unshift/shiftは配列の先頭の要素を操作する関数です
- 配列の先頭に要素を追加するときはunshiftを利用します
- 配列の先頭から要素を取り出すときにはshiftを利用します
#!/usr/bin/env perl use strict; use warnings; my @members = ( 'Alice', 'Bob' ); unshift @members, 'Carol'; print "@members" . "\n"; my @member = shift @members; print "@members" . "\n"; print "@member" . "\n";
- 出力結果
Carol Alice Bob Alice Bob Carol
ハッシュ
ハッシュの作成
- perlのデータ構造の1つで、配列と同じく要素の格納・取り出しができます
- ただし、配列と異なり名前(key)と値(value)のペアで格納されます
- このペアのことを要素と呼びます
- 名前(key)と値(value)の間にある
=>はファットコンマ演算子と呼ばれ、コンマと同等の役割を果たします- そのため
,でも動作しますが、配列との見分けが難しくなります
- そのため
# カンマで記載 my %hash = ( 'name)', 'Larry', 'birth', 1954, ); # ファットコンマ演算子で記載 my %hash = ( 'name' => 'Larry', 'birth' => 1954, );
- 名前(key)は文字列と解釈されます
- そのためシングルクォーテーションやダブルクォーテーションで囲む必要はありません
- ハッシュから要素を取り出す場合は波括弧
{ }を使います
my %hash = ( name => 'Larry', birth => 1954, ); print "$hash{name}\n"; print "$hash{birth}\n";
- ハッシュに要素を追加する場合は取り出すときと同様に{key}を使います
my %hash = ( name => 'Larry', birth => 1954, ); $hash{lang} = 'Perl'; print "$hash{lang}\n";
- ハッシュの中身を全部見る場合は
Data::Dumperモジュールを利用します
use Data::Dumper; my %hash = ( name => 'Larry', birth => 1954, lang => 'Perl', );
ハッシュの操作
- keys
- ハッシュの名前(key)の集合を返す
- delete
- ハッシュの要素を削除する
- exists
- ハッシュの要素が存在するかしないかを返す
keys
- ハッシュの名前(key)を配列にして返します
- keysは名前(key)を順不同、順番が不定で返します
#!/usr/bin/env perl use strict; use warnings; my %hash = ( name => 'Larry', birth => 1954, lang => 'Perl', ); my @keys = keys %hash; print "@keys\n"
- 出力結果
birth name lang
delete
- 指定したハッシュの名前(key)と、それに対応する値(value)を削除します
#!/usr/bin/env perl use strict; use warnings; my %hash = ( name => 'Larry', birth => 1954, lang => 'Perl', ); delete $hash{lang}; print "$hash{lang}\n"
- 出力結果
Use of uninitialized value $hash{"lang"} in concatenation (.) or string at hash_delete.pl line 12.
exist
- 指定したハッシュの名前(key)が存在するか確認します
- 名前(key)が存在すれば1(真)を返します
- 名前(key)が存在しなければ' '(空文字、偽)を返します
#!/usr/bin/env perl use strict; use warnings; my %hash = ( name => 'Larry', birth => 1954, lang => 'Perl', ); if ( exists $hash{name} ) { print "exists\n" } if ( exists $hash{foo} ) { print "exists\n" }
- 出力結果
exists
サブルーチン
サブルーチンとは?
- プログラムの中で、意味や内容がまとまっている作業をひとかたまりにしたものをサブルーチンと呼びます
- Perlにおけるサブルーチンは「関数」とほぼ同義です
サブルーチンの定義
- サブルーチンを定義するには
sub サブルーチン名 { ... }と書きます- 定義時に末尾に
;は不要です
- 定義時に末尾に
サブルーチンの呼び出し
- 定義したサブルーチンは定義したサブルーチン名の後ろに()をつけることでりようできます
サブルーチン名();
- サブルーチンに値(引数)を渡したい場合、()の中に書きます
- サブルーチンに与えられた引数は
@_という配列に格納されます@_は省略することもできます
sub say { my $str = shift @_; print "$str\n"; } say('Hello Perl');
- サブルーチンに複数の引数を渡すこともできます
sub plus { my ($first, $second) = @_; return $first + $second } my $result = plus(2, 5); print $result . "\n";
リファレンス
- リファレンスを利用することで配列やハッシュをスカラー変数として扱うことができます
- リファレンスの作り方は以下の2つがあります
my @alice_source = ( 60, 90 ); my $alice_source_ref = \@alice_source;
my %alice = ( name => 'Alice', japanese => 60, math => 90 ); my $alice_ref = \%alice;
- 無名配列・無名ハッシュとしてデータを直接リファレンスとして格納する方法
- 配列の場合は右のリストが
[ ]で囲う - ハッシュの場合は右辺のリストが
{ }で囲う
- 配列の場合は右のリストが
my $alice_source_ref = [ 60, 90 ];
my $alice_ref = { name => 'Alice', japanese => 60, math => 90 };
- リファレンスで複雑なデータ構造を作成
- リファレンスはprintだけでは確認できないためData::Dumperモジュールを利用します
#!/usr/bin/env perl use strict; use warnings; use Data::Dumper; my %alice = ( name => 'Alice', japanese => 60, math => 90 ); my $alice_ref = \%alice; my %bob = ( name => 'Bob', japanese => 60, math => 90 ); my $bob_ref = \%bob; my %charie = ( name => 'Charie', japanese => 60, math => 90 ); my $charie_ref = \%charie; my @array = ( $alice_ref, $bob_ref, $charie_ref ); print Dumper \@array;
デリファレンス
#!/usr/bin/env perl use strict; use warnings; use Data::Dumper; # 配列をデリファレンス my @alice_source = ( 60, 90 ); my $alice_source_ref = \@alice_source; my @alice_source_deref = @{$alice_source_ref}; print $alice_source_deref[0] . "\n"; # アロー記法で配列のデータを取り出す print $alice_source_ref->[0] . "\n"; # ハッシュをデリファレンス my %alice = ( name => 'Alice', japanese => 60, math => 90 ); my $alice_ref = \%alice; my %alice_deref = %{$alice_ref}; print $alice_deref{name} . "\n"; # アロー記法でハッシュのデータを取り出す print $alice_ref->{name} . "\n";
正規表現
- Perlは他のプログラミング言語と比べて正規表現が書きやすい言語である
- 正規表現を利用して条件に合致するかをテストするためには以下のように専用の演算子を利用します
=~の左辺に比較したい文字列を記述- 右辺に正規表現を
//で囲って記述
#!/usr/bin/env perl use strict; use warnings; # pで始まりlで終わる4文字の単語がマッチするかのテスト if ('perl' =~ /p..l/){ print "match" . "\n"; }else{ print "no match" . "\n"; }
- 正規表現を
()で囲むことでマッチした文字列を取得できます(キャプチャと呼ぶ)- キャプチャされた文字列は
$1という特殊変数に格納されます - 複数キャプチャすることも可能であり、その時はマッチした文字列が$1,$2...と順番に変数に格納されます
- キャプチャされた文字列は
# 正規表現にマッチする文字列を取得 if ('perl girl' =~ /(p..l)/){ print $1 . "\n"; }else{ print "no match" . "\n"; }
- 取得したい文字列は決まっているが、それとは別にグループ化だけしておきたい場面ではキャプチャしないグループ化である
(?:)を利用する
if ('perl girl' =~ /(?:p..l) (g..l)/){ print $1 . "\n"; }else{ print "no match" . "\n"; }
- 正規表現を用いてマッチした文字列の置換も行うこともできます
my $greet = "Hello! Alice"; $greet =~ s/Alice/Perl/; print $greet . "\n";
- 区切り記法を変更することもできます
- 正規表現で用いる区切り文字
/とURLやpathの区切り文字である/が混在する場合は{}に変更できます - マッチを探す際も
m{}と書くことで区切り文字を変更可能です
- 正規表現で用いる区切り文字
my $path = '/usr/local/bin/perl'; $path =~ s{/usr/local/bin/}{/usr/bin/}; print $path . "\n"; if ('perl girl' =~ m{p..l}) { print "match" . "\n"; }else{ print "no match" . "\n"; }
- 大文字小文字問わず検索したい場合perlではi修飾子を使うことで大文字小文字を区別せずに検索できます
if ('Perl' =~ /p..l/i) { print "match" . "\n"; }else{ print "no match" . "\n"; }
PerlでWeb API
HTTP:Tiny
JSON:PP
気象庁非公式Web APIを利用
#!/usr/bin/env perl use strict; use warnings; use Data::Dumper; use HTTP::Tiny; use JSON::PP; my $url = 'https://www.jma.go.jp/bosai/forecast/data/overview_forecast/130000.json'; my $response = HTTP::Tiny->new()->get($url); my $content = $response->{content}; my $decoded_content = JSON::PP->new->decode($content); print $decoded_content->{targetArea};
Private Automation HubへのLDAP設定方法について
概要
- AWX/Ansible Automation ControllerではGUIでLDAP設定を行いますが、Private Automation HubではInstall時のInventoryに記載する必要がありました。
- その時の設定例をご紹介します。
環境
- 使用インストーラ
- ansible-automation-platform-setup-bundle-2.4-1-x86_64.tar
- Private Automation Hub
- 4.9.2
- Windows Server 2022
Private Automation HubへのLDAP認証設定
- Installerの中にある
inventoryファイルに下記の項目を記載
automationhub_authentication_backend = "ldap" automationhub_ldap_server_uri = "ldap://192.168.48.132" automationhub_ldap_bind_dn = "CN=ldap,CN=Users,DC=hii,DC=com" automationhub_ldap_bind_password = "<password>" automationhub_ldap_user_search_base_dn = "DC=hii,DC=com" automationhub_ldap_group_search_base_dn = "DC=hii,DC=com" automationhub_ldap_user_search_scope="SUBTREE" automationhub_ldap_user_search_filter="(sAMAccountName=%(user)s)" automationhub_ldap_group_search_scope="SUBTREE" automationhub_ldap_group_search_filter="(objectClass=group)" automationhub_ldap_group_type_class="django_auth_ldap.config:ActiveDirectoryGroupType"
LDAPの設定については下記の記事を参照してください
さいごに
Private Automation HubのLDAP認証設定もGUIで実施できるようにしてほしいなぁ。。
Inventoryわかりづらいし、設定変更のたびにインストーラー実行するのはハードル高い。。
Ansibleのdefaultフィルターの使い方と挙動について
概要
- Ansibleで利用できるdefaultフィルターの使い方と使用した際の挙動についてご紹介します。
- Ansibleの公式サイトもご参考までに!
環境
- ansible 2.16.6
defaultフィルターについて
Ansibleのモジュールを利用する際に、パラメータとしてデフォルト値を設定したいと思ったことはありませんか?
その際にデフォルト値を設定しておけるdefaultフィルターを使ったPlaybooの記載方法と出力結果は以下になります。
Sample Playbook
--- - name: "default filter and omit variables usage" hosts: "localhost" gather_facts: false vars: var1: "指定した値" var2: "デフォルト値" var3: "" tasks: - name: "値を指定している為、デフォルト値が使われないパターン" ansible.builtin.debug: var: var1 | default(var2) - name: "値を指定していないため(指定の変数が定義されていない)、デフォルト値が使われるパターン" ansible.builtin.debug: var: var4 | default(var2) - name: "変数で空を定義している場合はそのまま空が使われるパターン" ansible.builtin.debug: var: var3 | default(var2) - name: "変数が空の場合はデフォルト値を使用したいパターン" ansible.builtin.debug: var: var3 | default(var2, true)
出力結果
PLAY [default filter and omit variables usage] *********************************
TASK [値を指定している為、デフォルト値が使われないパターン] ********************
ok: [localhost] => {
"var1 | default(var2)": "指定した値"
}
TASK [値を指定していないため(指定の変数が定義されていない)、デフォルト値が使われるパターン] ***
ok: [localhost] => {
"var4 | default(var2)": "デフォルト値"
}
TASK [変数で空を定義している場合はそのまま空が使われるパターン] ****************
ok: [localhost] => {
"var3 | default(var2)": ""
}
TASK [変数が空の場合はデフォルト値を使用したいパターン] ************************
ok: [localhost] => {
"var3 | default(var2, true)": "デフォルト値"
}
PLAY RECAP *********************************************************************
localhost : ok=4 changed=0 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
Ansible NavigatorでAnsible Vaultの使い方
ansible-navigatorコマンドを利用してAnsible Vaultで暗号化したい
概要
- ansible-navigatorコマンドを用いたAnsible Vaultの利用方法
環境
- ansible-navigator
- 24.2.0
Ansible NavigatorでAnsible Vault実行
- 下記のような記載で今まで通りの
ansible-vaultコマンドを使うことができる
ansible-navigator exec -- ansible-vault
- 任意の文字列を暗号化する場合は以下
ansible-navigator exec -- ansible-vault encrypt_string 'password'